외부 라이브러리를 사용하지 않는 것을 기준으로 작성
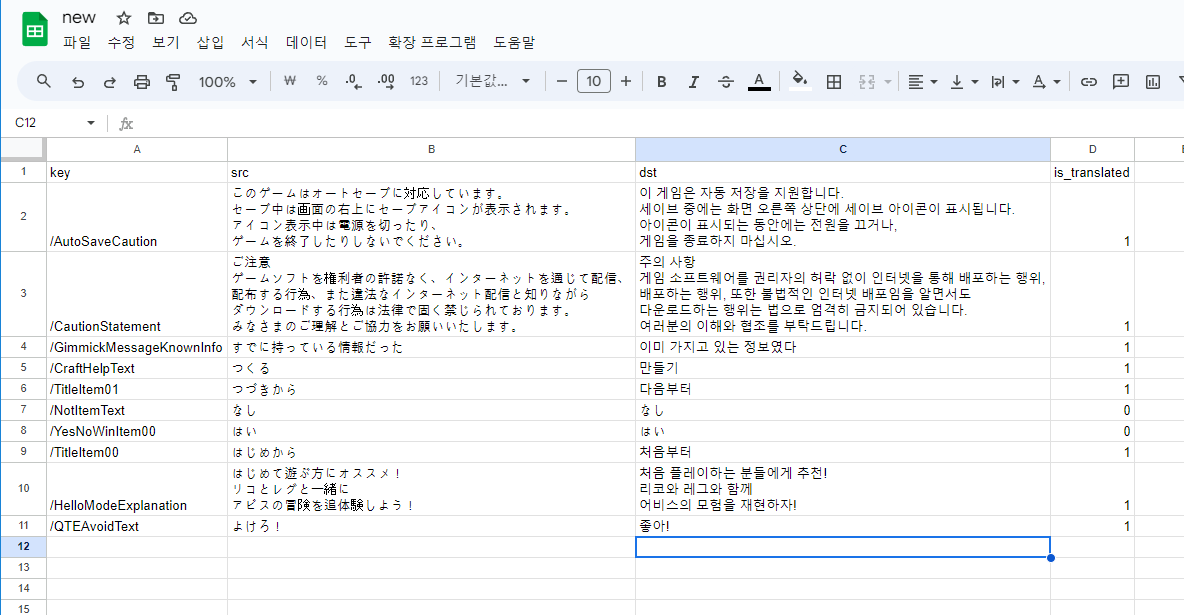
이런 형태의 csv파일이 있다고 가정한다.
기본작업

우선 권한을 '링크가 있는 모든 사용자'로 업데이트한다.
이래야 링크를 통한 접근이 가능해진다.
그다음, csv로 저장할지 바로 사용할지에 따라 방법이 갈린다.
1) 데이터를 csv 파일로 저장하여 사용하기
import urllib.request
import csv
doc_id = "1TeL3R5cmkSGt-Ynn9bmuF05n00W-ufONOaEGFV9uMw4"
sheet_id = "883734849"
url = f"https://docs.google.com/spreadsheets/d/{doc_id}/export?format=csv&gid={sheet_id}"
output_file = "test.csv"
urllib.request.urlretrieve(url, output_file)
with open(output_file, "r", encoding="utf-8") as f:
reader = csv.reader(f)
next(reader) # skip header
for row in reader:
print(row)스프레드시트 화면에서 상단 주소표시줄을 보면
이런 형식의 주소가 보인다.
위 예시에서 doc_id는 /d/ 및 /edit 사이에 껴있는 1TeL3R5cmkSGt-Ynn9bmuF05n00W-ufONOaEGFV9uMw4이고
sheet_id는 gid= 뒤에 있는 883734849이다.

실행을 해보면 csv파일이 제대로 받아진 걸 볼 수 있다.
2) 데이터를 바로 읽어들여 사용하기
import urllib.request
import csv
import io
doc_id = "1TeL3R5cmkSGt-Ynn9bmuF05n00W-ufONOaEGFV9uMw4"
sheet_id = "883734849"
url = f"https://docs.google.com/spreadsheets/d/{doc_id}/export?format=csv&gid={sheet_id}"
response = urllib.request.urlopen(url)
data = response.read().decode("utf-8")
data = io.StringIO(data)
reader = csv.reader(data)
next(reader) # skip header
for row in reader:
print(row)urlretrieve가 아닌, urlopen을 사용하는 방법이다.
마찬가지로, 스프레드시트 화면에서 상단 주소표시줄을 보면
이런 형식의 주소가 보인다.
위 예시에서 doc_id는 /d/ 및 /edit 사이에 껴있는 1TeL3R5cmkSGt-Ynn9bmuF05n00W-ufONOaEGFV9uMw4이고
sheet_id는 gid= 뒤에 있는 883734849이다.

실행을 해보면 csv 데이터가 정상적으로 읽히는 것을 볼 수 있다.
'python snippets' 카테고리의 다른 글
| Python 3.12에서 ImportError: No module named matplotlib 에러가 뜰 때 (1) | 2023.10.27 |
|---|---|
| Python으로 문자 일괄치환 (0) | 2023.09.30 |
| Python으로 ix.io에 데이터 올리기 (1) | 2022.09.30 |