텍스트가 존재하는 번들 파일의 암호화/복호화 및 일본어 함수명을 가진 Lua 5.1 파일의 수정법을 알아봅시다.
0. 준비 프로그램
- AssetStudio
- UABEA
- luac
- unluac
1. 기초 분석
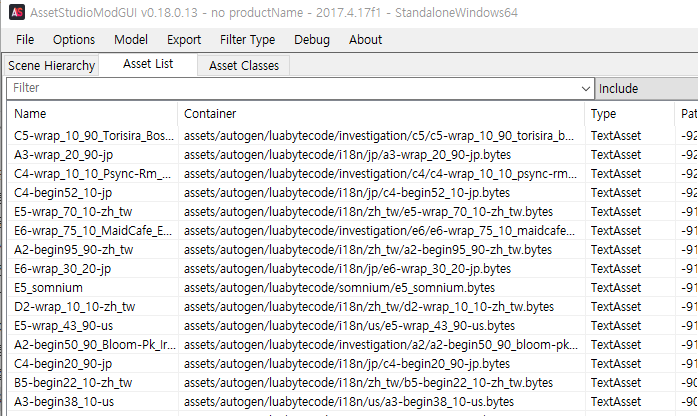
에셋번들의 luabytecode 번들을 열어보면, 위와 같은 구성으로 되어 있는걸 알 수 있습니다.
컨테이너 -> assets/autogen/luabytecode/~.bytes 파일입니다.


bytes 파일답게 내용이 바로 보이지 않습니다.
Lua 시그니쳐를 가지고 있습니다.
앞으로 보나 뒤로 보나 Luac 파일입니다.

이상합니다. 디스어셈블, 디컴파일 모두 안됩니다.
모종의 암호화가 되어있다는 소리입니다.
다행히도, 게임이 Mono 게임이라 뜯어보기는 쉽습니다.

ilspy로 코드를 솔루션으로 일괄추출한 다음, notepad++로 검색을 돌렸습니다.
컨테이너 패스로 검색을 돌리니 바로 튀어나옵니다.
에셋을 로드한 다음, 파일의 5바이트부터 0xFF로 xor을 돌리는 모습입니다.
파이썬 코드로 구현하면 다음과 같은 모습이 되겠습니다.
def xor_process_data(data, start_position=4):
buffer = bytearray(data)
for position in range(len(buffer)):
if position >= start_position:
buffer[position] ^= (position & 0xff)
return bytes(buffer)
2. 복호화 작업
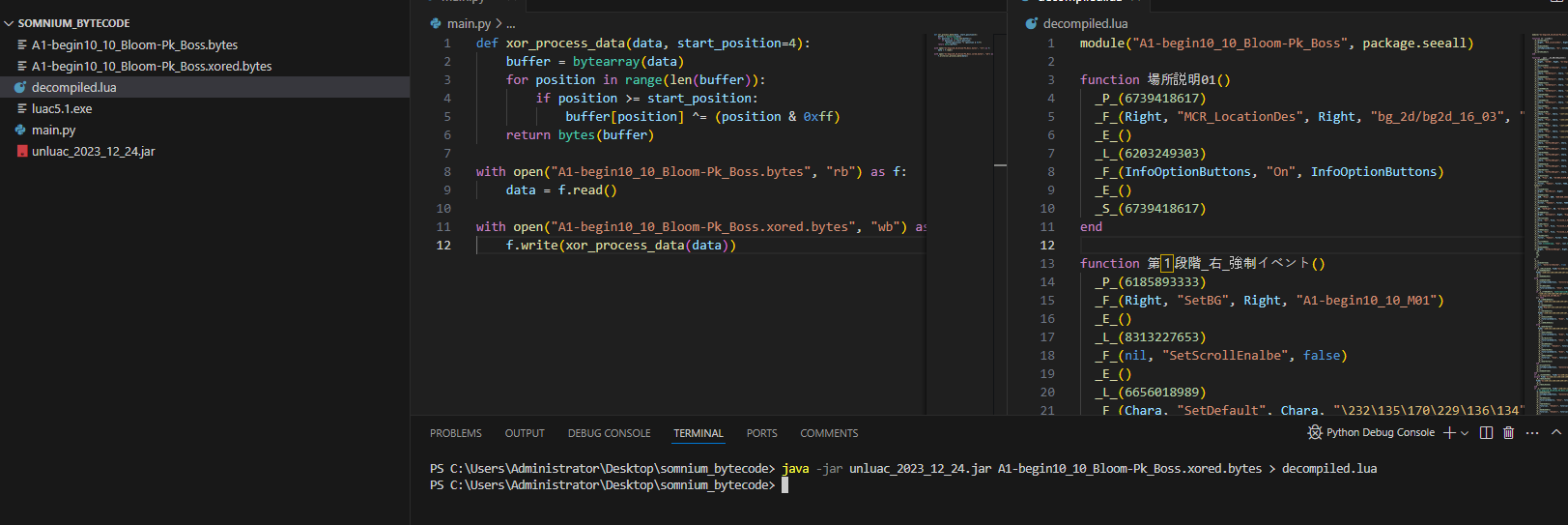
위 코드로 xor 복호화를 하고 (xor은 암호화와 복호화 과정이 똑같습니다.)
3. 디컴파일/디스어셈블 작업
unluac.jar로 디컴파일 코드를 뽑아내 보았습니다.
잘 뽑혀나옵니다.
디컴파일은 아래 명령어를 통해 하면 됩니다.
:: ex) java -jar unluac_2023_12_24.jar --rawstring A1-begin10_10_Bloom-Pk_Boss.xored.bytes > decompiled.lua
java -jar <unluac_jar파일> --rawstring <인풋_파일> > <아웃풋_파일>
근데 뭔가 이상합니다.
함수명이 일본어를 비롯한 비-ascii 문자로 도배가 되어있습니다.

luac.exe를 통해 컴파일을 하려고 해봤는데, 역시나 3번째 라인에서 문제가 발생합니다.
그래서 luac.exe의 소스를 받아서 유니코드 지원도 시켜보고, 별 짓을 다 해봤지만 문제가 발생했습니다.
심지어, 함수 이름 및 함수 사용 부분을 임의의 영어로 변환하거나, local 테이블을 만들어 함수를 할당시켜도 봤습니다.
하지만 계속 문제가 발생했습니다.
그러다가 문득 예전에 작업했었던 모 게임이 떠올랐습니다.

얘는 디컴파일 시 goto문으로 디컴파일이 되는데, 정작 컴파일 시 goto문이 지원을 안해서
디컴파일이 아니라 디스어셈블리 작업을 했었습니다.
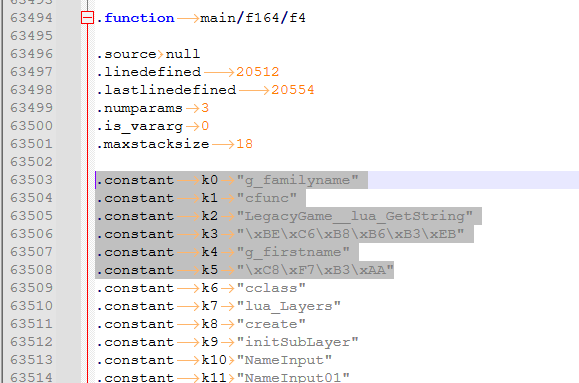

디스어셈블을 하면 이런 식으로 보입니다.
디스어셈블은 기계어 코드를 어셈블리어로 바로 직역하는 거라고 보심 됩니다.
그에 비해 디컴파일은 원래 작성되었던 고수준 언어로 번역하는 거라고 보심 됩니다.
당연히 사람이 이해하기는 디컴파일 된 코드가 쉽지만, 수정은 디스어셈블-어셈블을 통해 하는 것이 신뢰도가 높습니다.
아무튼, 이 게임이 떠오른 관계로,
AI The Somnium Files의 컴파일이 안되는 luac 파일도 디스어셈블을 한 다음
수정할 부분을 수정하고 어셈블을 하면 되지 않을까 싶었습니다.

:: 예시) java -jar unluac_2023_12_24.jar --disassemble A1-begin10_10_Bloom-Pk_Boss.xored.bytes > disassembled.lua
java -jar <unluac_jar파일> --disassemble <인풋_파일> > <아웃풋_파일>디스어셈블은 위 명령어를 통해 하면 됩니다.
이럴수가. 이스케이프 지옥에 빠졌습니다.
저걸 어떻게 사람이 봅니까. 당장 변환하는 코드를 짜고자 했습니다.
근데 모든 상수를 다 추출할 필요는 없다고 생각해서, 일단 디컴파일된 코드부터 살펴봤습니다.

이 파일에서 변경을 목표하던 챕터명은
" _F_(ChapterTitle, "SetText", ChapterTitle, "1日目:金曜日", "屍骸", "sigAI")"와 같은 코드로 짜여있었습니다.
여기서 떠오른 아이디어가,
1. 디컴파일 된 코드에서 챕터명/엔딩명을 csv로 추출
2. 디스어셈블된 코드의 .constant를 읽으며, 이스케이프된 문자열을 원상복구
3. 원상복구한 문자열이 1번에서 추출한 csv와 동일하면, csv의 번역문을 이스케이프한 상태로 삽입
이런 과정을 거치는 것이었습니다.
4. 텍스트 교체 작업

일단 첫번째를 해결해보자면,
파일명: 내용의 형태로 정상적으로 출력되는 것을 확인했습니다.
모든 줄을 읽어와서 순회하며 ", "를 기준으로 나누고, 만약 라인의 1번 요소가 "SetText", 2번 요소가 ChapterEnd 혹은 ChapterTitle이라면 추출되도록 했더니, 제대로 출력이 되고 CSV에도 정상적으로 기록이 됐습니다.

2, 3번을 위해 테스트를 해봤습니다.
원본 문자열을 bytes로 바꾸고, unicode_escape시킨 후, latin1로 인코드하고, 그걸 다시 utf-8로 디코드하면 원본 문자열이 보입니다.
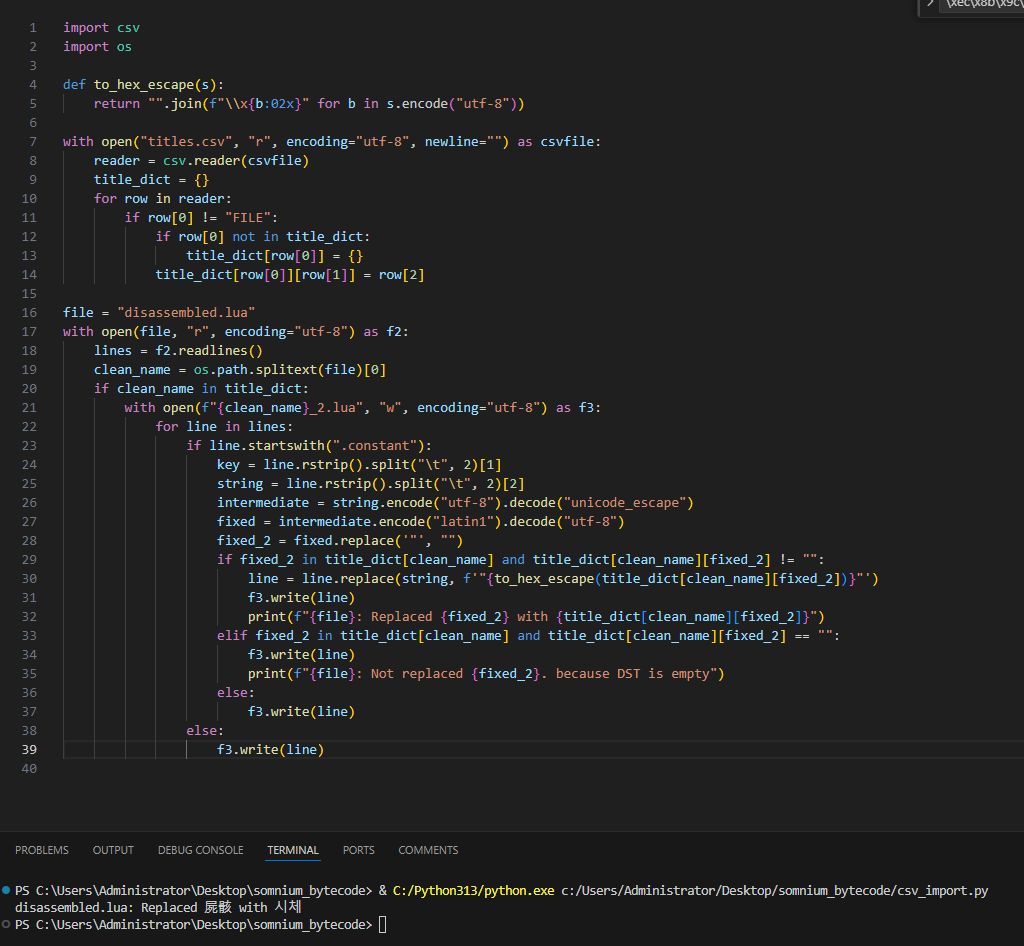
문자열을 이스케이프하는 함수를 하나 짜고, 위에서 테스트한 것을 활용하여
만약 번역문이 있다면 번역문을 이스케이프하여 원본과 replace하는 코드를 짰습니다.
屍骸가 시체로 제대로 변환됐다고 합니다.
WinMerge를 통해 확인해봅시다.
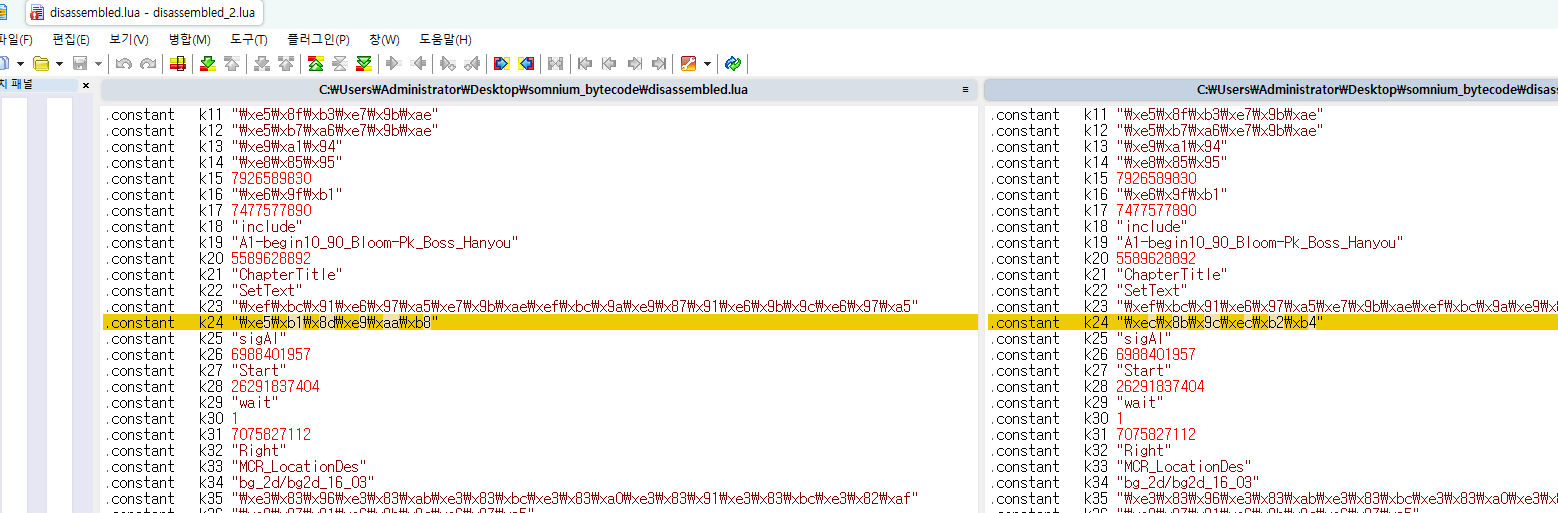
완벽하게 바뀐 걸 확인할 수 있습니다.
5. 어셈블/재암호화/이식작업

어셈블 명령어는 간단합니다.
:: 예시) java -jar unluac_2023_12_24.jar --assemble .\disassembled_2.lua --output assembled.luac
java -jar <unluac_jar파일> --assemble <인풋_파일> --output <아웃풋_파일>
이제 2번의 <2. 복호화 작업> 에서 했었던 xor을 다시 해줍니다.
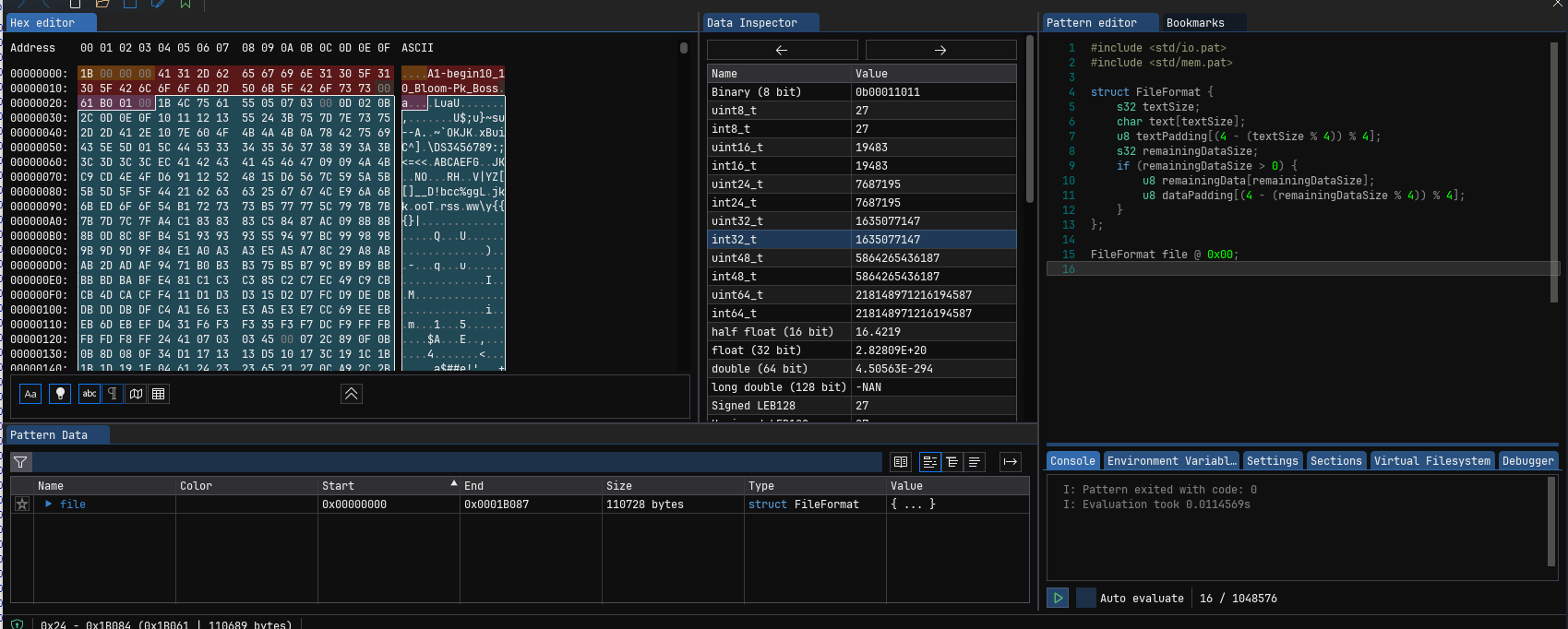
위 사진은 유니티 TextAsset을 UABEA로 추출했을 때의 기본 구조입니다.
- TextAsset 이름의 크기를 나타내는 4바이트(패딩 제외),
- TextAsset의 이름 + 4바이트 단위 패딩(4바이트씩 맞아떨어지도록 0x00을 추가)
- 데이터의 크기(패딩 제외)
- 데이터 + 4바이트 단위 패딩
으로 이루어져 있습니다.
그러니까, 위 사진 기준, 데이터의 시작 위치는 0x00000024부터니까
1. 위에서 xor한 파일의 크기 알아내기
2. 실제 데이터 시작 위치인 0x00000024부터 xor한 데이터를 이식함
3. 데이터 끝으로 가서 4바이트 기준 0x00 패딩
4. 데이터의 크기를 나타내는 0x00000020부터 4바이트의 크기를 수정
하면 UABEA용 Raw Import 이식이 끝납니다.
사실 저는 UnityEX 있어서 이 귀찮은 작업은 스킵했습니다.
다만, 파이썬으로 매우 쉽게 작성이 가능합니다.
6. 테스트

귀찮아서 바로 테스트 할 수 있는 부분으로 테스트했습니다.
타이틀명이 제대로 바뀌었고, 버그도 없는 걸 볼 수 있습니다.
'한글화 분석 (작업X)' 카테고리의 다른 글
| Quake 2021 Remastered 메인메뉴 한글 출력 (0) | 2025.04.13 |
|---|---|
| Harvest Moon The Winds of Anthos (0) | 2023.12.10 |
| sailing era 한글화 분석 (57) | 2023.08.01 |
| Angry Video Game Nerd II: ASSimilation 한글화 분석 (0) | 2023.04.06 |