상당히 졸리므로 간단하게만 짚고 넘어가겠습니다.

원본
띄어쓰기를 통해, 한글이 정상적으로 인식되나 출력이 이상하다는 걸 알 수 있습니다.
"멀티 플레이"가 "?? ???"으로 나오기 때문에, 단순한 싱글바이트/멀티바이트 인식 문제는 아닙니다. 출력부가 잘못됐으리라 예상합시다.
디버그를 걸고, 010에디터에서 텍스트를 검색하고, 텍스트가 있는 위치에 브레이크포인트를 걸어서 뭔 함수들이 읽어들이나 분석해봅니다.

여러가지 동적 분석, 정적 분석을 통해 sub_1401970C0 함수가 ImGUI 초기화 및 메인메뉴의 폰트 아틀라스를 구성하는 ImGUI의 함수란걸 알았습니다.
이제 mov qword ptr [rsp+230h+advance_x], r14 형태로 전달되는 글리프 범위 (6번 인자)를
KS1001+영문자+특수기호로 패치해봅시다.
import struct
text_data = open("korean.txt", "r", encoding="utf-8").read()
unique_chars = set()
for char in text_data:
unique_chars.add(char)
sorted_codepoints = sorted([ord(c) for c in unique_chars])
ranges = []
range_start = sorted_codepoints[0]
current_range_end = sorted_codepoints[0]
for i in range(1, len(sorted_codepoints)):
if sorted_codepoints[i] == current_range_end + 1:
current_range_end = sorted_codepoints[i]
else:
ranges.extend([range_start, current_range_end])
range_start = sorted_codepoints[i]
current_range_end = sorted_codepoints[i]
ranges.extend([range_start, current_range_end])
ranges.append(0)
byte_sequence = b''
for val in ranges:
byte_sequence += struct.pack('<H', val)
with open("ks_ranges.bin", 'wb') as f_out:
f_out.write(byte_sequence)일단 다운받은 KS1001 텍스트 파일에서 unicode range 추출, ImGUI 형식에 맞게 바이너리로 변환

0A 00 부분은 필요없으니 제거하고 나머지 복사

CFF Explorer로 .patch 섹션 추가, 범위는 좀 널널하게
위에서 나온 bin파일 + @로

코드 케이브에서 코드 실행이 가능해야 하니까 Is executable 체크
그 다음 확장된 섹션에 아까 복사했던 글리프 범위 데이터 덮어쓰기
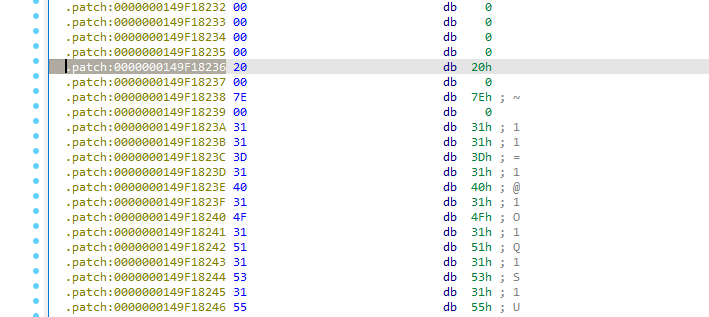
ida에 리로드시켜서 글리프 데이터 위치 확인 (0x149F18236)

.patch 섹션에 코드케이브 파놓기 (아까 봐뒀던 글리프 데이터 시작 위치를 mov rax, {데이터위치}로 넣어줌)
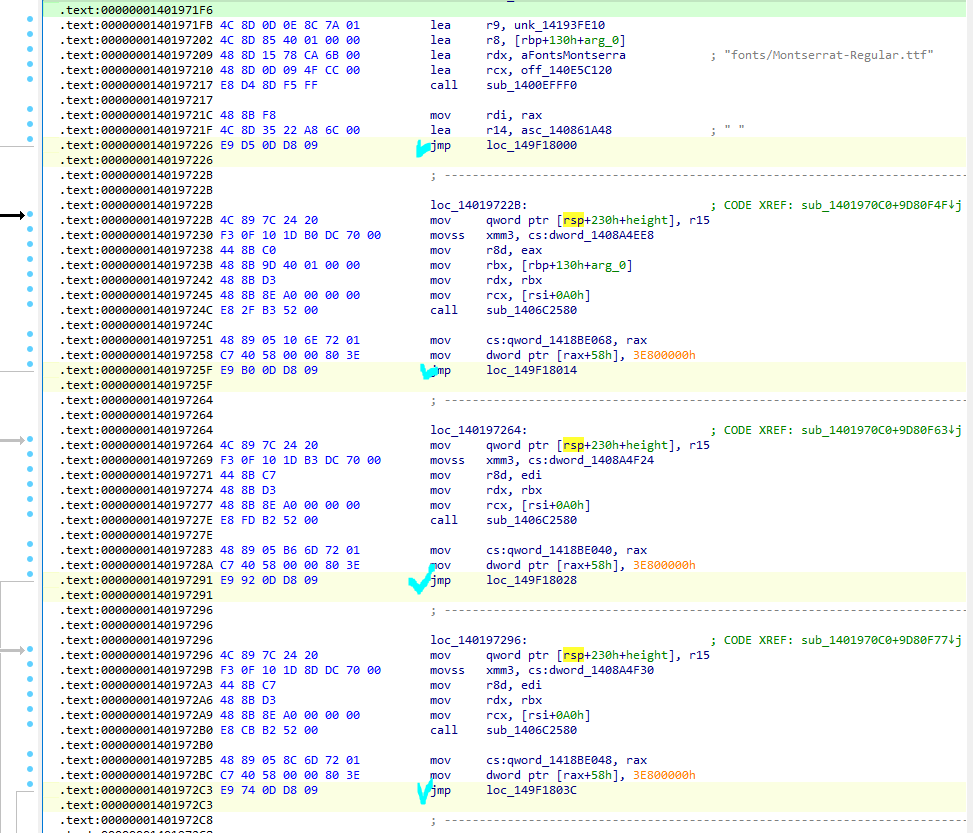
mov qword ptr [rsp+230h+advance_x], r14 형태의 5바이트 바이트코드를 jmp {코드케이브 주소}로 대체 (같은 5바이트)
4군데 다 교체

패치 적용

성공입니다
'한글화 분석 (작업X)' 카테고리의 다른 글
| AI The Somnium Files (0) | 2025.04.04 |
|---|---|
| Harvest Moon The Winds of Anthos (0) | 2023.12.10 |
| sailing era 한글화 분석 (57) | 2023.08.01 |
| Angry Video Game Nerd II: ASSimilation 한글화 분석 (0) | 2023.04.06 |